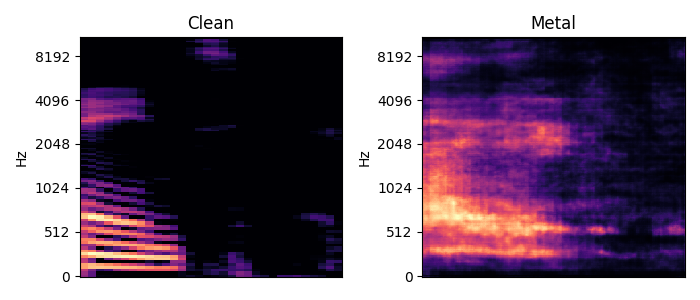
Scream Machine: Voice Conversion with an Artifical Neural Network
The human voice is one of the most versatile and arguably the most important instrument that we have at our disposal. Humans are capable of creating the wildest sounds, like polyphonic overtones or false cord activation. Especially the ladder is one of the most important techniques in metal vocals. But trying to find your entry into metal voice singing is hard. You have to learn completely new techniques and activate parts of your throat that you never thought existed. I thought: if I am not yet there, can I teach a machine to learn how to do it? So I set sail this semester to find out whether I can emulate metal vocals with a machine learning model.
The idea and the model
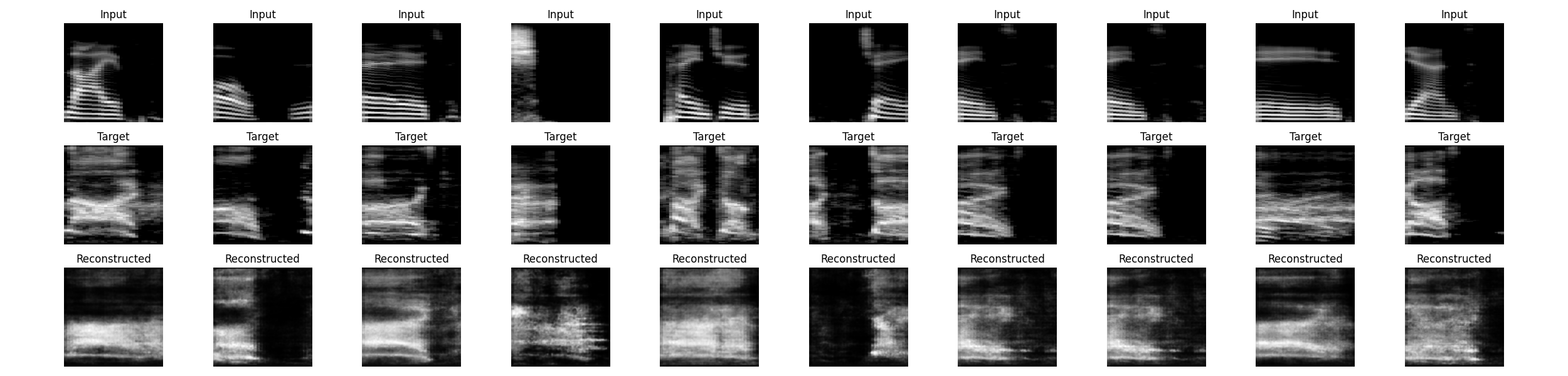
Let’s create a machine learning model that is trained on paired input data of a clean voice and the metal vocal version of it. The trained model would then generate the metal vocal equivalent if given the clean voice as new input. I decided to go with a Variational Autoencoder framework because of it’s reconstruction capabilities, relatively lightweight architecture and the possibility to feed it images of spectrograms which drastically reduces training and inference time. The idea is simple: feed my clean voice into the model and define the metal vocals as target, so that the autoencoder learns to reconstruct the metal vocals from my voice.
The dataset
The hardest part of this project was to find the right dataset. In order to be trained effectively, your model needs lots of data. First, I thought to just record myself speaking over two hours and send the recording through a distortion effect. While this would have yielded enough data I would have ended up with only teaching the model to learn to recreated the distortion effect and not all the intricacies and different timbres metal vocals have to offer. So I decided to go the hard way and re-record the lyrics of an entire album with my own voice. This is very ineffective since I have to manually align both tracks, otherwise the model would not get the correlations between the two voices. I chose to record one of my favourite albums of all times, Fear Factory’s ‘Soul of a New Machine’. After the preprocessing stage, which includes generating melspectrogram images of the inputs and targets, I started to explore a fitting model architecture.
The outcome
Since this was an exploration towards the limit of what is possible with a very small dataset and a lightweight architecture, I am pretty happy with the results. You can see that the model was able to learn from my data and transpose some of my input and target properties to the reconstruction. There is much room for improvement though which could include additionally passing Melspectrogram Cepstral Coefficients (MFCC’s) to the input layer and obviously, expanding my dataset.
Now, listening to the outcome of the image-to-audio algorithm (the librosa version of the Griffin-Lim algorithm) reveals another field for improvement: data loss. Although the visual reconstruction is quite acceptable, the audio reconstruction lacks the phase component of the original signal as well as form and clarity. Hear for yourself:
Nevertheless, I think the results are promising and I am looking forward to implementing another iteration of my idea.
Input to input reconstruction:
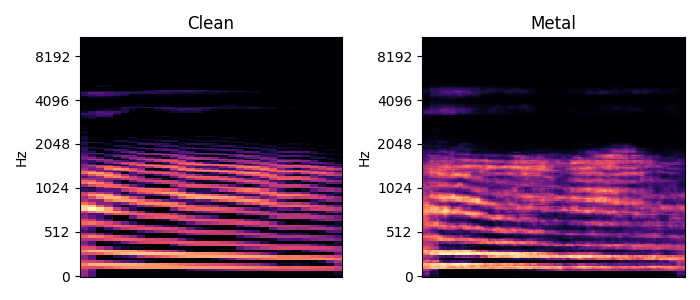
Input to target reconstruction: