Spotlight: AutoEncoders and Variational AutoEncoders
Spotlight: AutoEncoders and Variational AutoEncoders
Since we all prayed to the Autoencoder god this semester we thought about giving you an introduction to the architecture and capabilities of autoencoders and their sibling the variational autoencoder. Especially VAE’s have become extremely popular over the last years, capable of creating entirely non-existing human faces and purely synthetic music.
To generate or not to generate
Generative deep learning models are a type of artificial neural network that can learn to generate new data samples similar to the training data provided. These models are designed to learn the underlying patterns and structure of the data, which can then be used to create new samples. If you dive a little bit deeper into the matter you will find the information on the internet that the vanilla autoencoder cannot be used for generative purposes. If we define “generative” as the ability to create data then it is absolutely true that an autoencoder can be used for generative purposes. The thing is that it is just does not work very well with creating continuous data. That’s were VAE’s come in.
Autoencoders
An autoencoder is a neural network structure with an equal number of inputs and outputs and at least one hidden layer which is smaller in size. It’s two main purposes are signal or image denoising and dimensionality reduction.
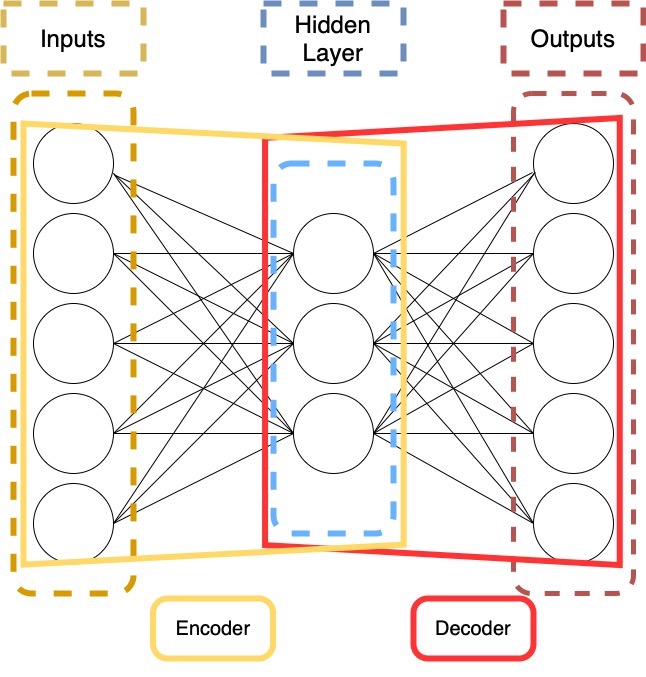
The structure of the AE effectively acts as a form of “compression” and “decompression” of the data. Importantly, these stages mirror each other. Many purposes use these to map one value to another. In a musical context, this can be used for accompaniment, mapping inputs of musical parts to desired outputs of accompanying parts, such as in the case of MiniBach.
This can also be used for purely generative purposes, if the desired output of the system is set to be the input. Here the system would essentially “learn” how to construct the input data via its encoder/decoder stages. In this way, an autoencoder is able to “learn” the rules of a dataset.
The smallest layer in the system, is often referred to as the “latent layer” or “bottleneck layer”. After training, we can use only the decoder layer to generate material by giving values into the bottleneck layer and having them fed-forward through the decoder stage generating new material based on the training data.
Variational Autoencoders
A variational autoencoder is very similar to a traditional autoencoder but with an important twist. Traditional autoencoder map the encoded data to a fixed point in the latent space which, when reconstructed by the decoder, will ideally produce a 1-to-1 reconstruction of the input data. That’s why autoencoders solely optimize reconstruction loss.
In a variational autoencoder the encoded data does not get mapped to a fixed point but to a probability distribution. This is were the true generative capability of a VAE lies. When this distribution is sampled and ran through the decoder it will generate a new sample resembling the input data, or anything you specify that lies in-between. Simplified, if you have a dataset that contains flute and guitar recordings, with sampling the latent space correctly you could essentially create an instrument that sounds a bit like a flute and a bit like a guitar.
To do this the model needs it’s own specialized loss function. The most common way of calculating loss in a VAE is by combining the reconstruction loss and Kullback-Leibler divergence. This divergence, which is also called KL divergence, essentially computes the “divergence” between two probability distributions (i.e., how much they look not like each other).
Conclusion
In summary, while both AEs and VAEs are neural networks that can be used for data compression and dimensionality reduction, VAEs go one step further by explicitly modeling the probability distribution of the latent space. This allows VAEs to generate new data samples from the learned distribution, making them particularly useful for generative tasks.
Sources
Dhinakaran, Aparna. 2023. “Understanding KL Divergence.” Medium. March 22, 2023. https://towardsdatascience.com/understanding-kl-divergence-f3ddc8dff254.