Breakbeat Science
Introduction
Generating audio with deep learning techniques can be quite a daunting task. To generate a single second of audio at a sample rate of 48kHz means you need to generate 48 000 separate samples. This quickly becomes computationally expensive, even if sample rate is lowered.
What if you instead of using raw audio, you used a visual representation of it? This is what I did in my project titled “VAmEn”. I used images of mel-spectrograms to generate audio samples of breakbeats using a Variational AutoEncoder (VAE). This is a simple but powerful machine learning architecture.
What is a Mel Spectrogram?
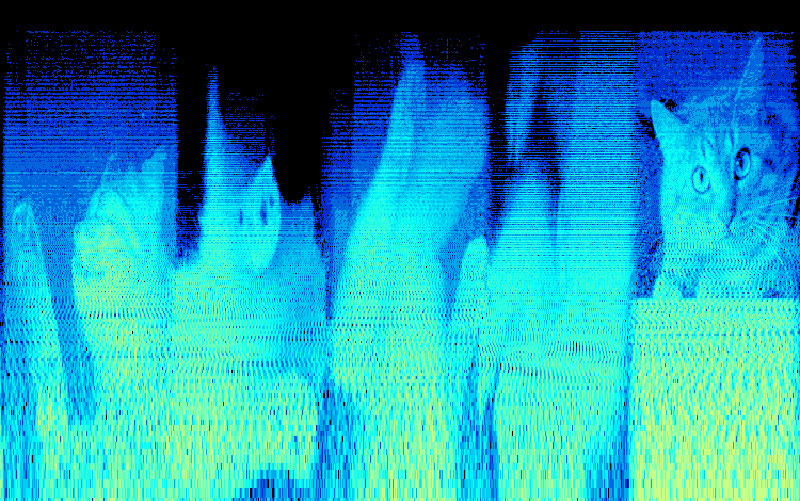
I mentioned I trained my model using mel spectrograms, but what it is? A mel spectrogram is a visual representation of sound that shows the energy at different frequencies over time.
It uses a non-linear mel scale to better represent how humans hear sound and the Fast Fourier Transform (FFT) to calculate the energy at each frequency. The resulting 2D image shows time on the horizontal axis, frequency on the vertical axis, and energy as color.
The final result would then be an image made out of pixels which is a lot less data than a raw audio file making it much easier for the machine to learn.
## Variational AutoEncoders
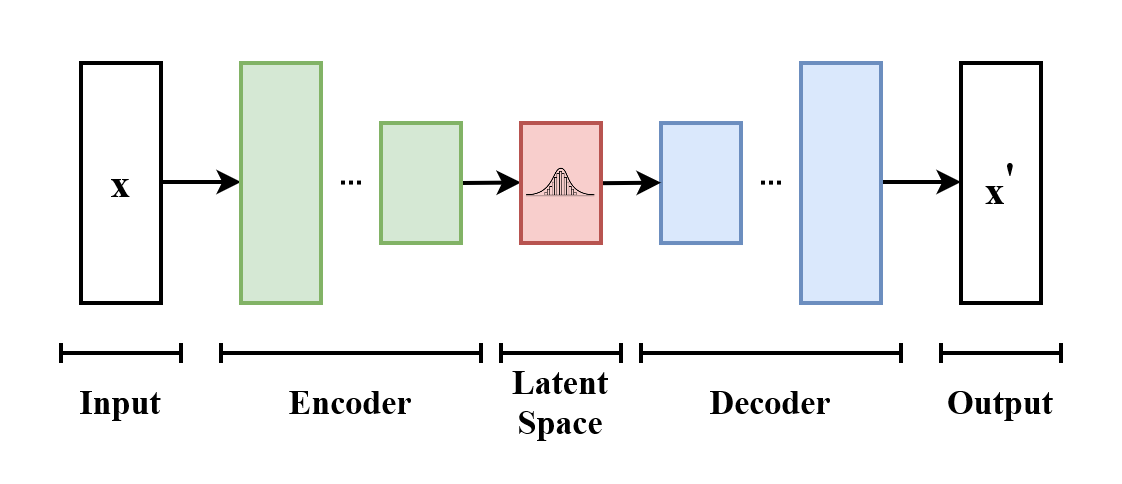
Variational AutoEncoders (VAEs) are a type of artificial neural network that can learn to represent high-dimensional data in a lower-dimensional space. They work by encoding input data into a lower-dimensional latent space, and then decoding it back into the original space.
VAEs use a probabilistic approach to encoding and decoding, allowing them to generate new data that resembles the input data. This makes them ideal for generative purposes. If you want to learn more about AEs and VAEs check out this post!
VAmEn
My goal was to create a model with the ability to generate mel spectrograms of breakbeats. I did this by training my model on a dataset I created consisting of almost 10 000 randomized amen break samples!
I extracted the mel spectrogram for each sample and gave these to my model. Since I used large 512x512 pixel images and almost 10k samples training took quite a while, even though I lowered the sample rate to 10kHz. I am lucky enough to own a decently powerful powerful GPU which sped up the training process. If you do not have GPU access I would recommend looking into Google Colab. Here you can get access to a remote GPU from Google to train your model.
Results
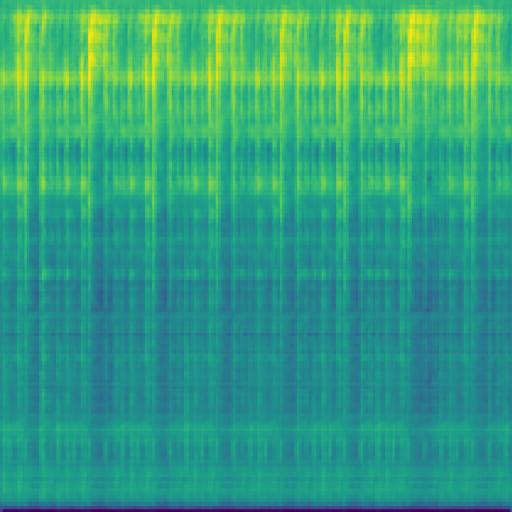
Once finished training the model was able to create quite good looking spectrograms by sampling the latent space, which sounded great. To turn my spectrogram into audio I used an algorithm called the Griffin-Lim algorithm which produced surprisingly good results. Take a listen!
Sources
Frenzel, Max. 2018. “The Variational Autoencoder as a Two-Player Game — Part I.” Medium. April 23, 2018. https://towardsdatascience.com/the-variational-autoencoder-as-a-two-player-game-part-i-4c3737f0987b.
Reducible, dir. 2020. The Fast Fourier Transform (FFT): Most Ingenious Algorithm Ever? https://www.youtube.com/watch?v=h7apO7q16V0.
Roberts, Leland. 2022. “Understanding the Mel Spectrogram.” Analytics Vidhya (blog). August 17, 2022. https://medium.com/analytics-vidhya/understanding-the-mel-spectrogram-fca2afa2ce53.
Bastwood, “The Aphex Face .” n.d. Accessed April 24, 2023. http://www.bastwood.com/?page_id=10.
“Variational Autoencoder.” 2023. In Wikipedia. https://en.wikipedia.org/w/index.php?title=Variational_autoencoder&oldid=1148033201.