Comparing MIDI Representations: The Battle Between Efficiency and Complexity

In my previous blog post, I wrote about different ways to represent MIDI for a neural network with the intent of generating melodic, symbolic music. You can read my previous post here. In that post I mentioned some drawbacks and benefits of different representations, but how can this be observed in the music that is generated? I have implemented three of these methods, and generated some melodies based on the representations. The results stem from three similar neural networks, with similar configurations in order to compare only the representations.
The representations
The three different representations I compared are 1D event based, piano roll and relative pitch. The main differences between the representations are that event based is a 1D representation, while piano roll and relative pitch are 2D. 1D representation for a neural network is suboptimal, but in return it is far more memory efficient. Piano roll quantizes MIDI into timesteps and represents each time step as a one hot encoded vector. It is the most complex representation, but with a very high memory consumption. Relative pitch is a continuation of piano roll, but only represents the transition data. For more detail about the methods, please check out my previous blog post.
Let’s start with training
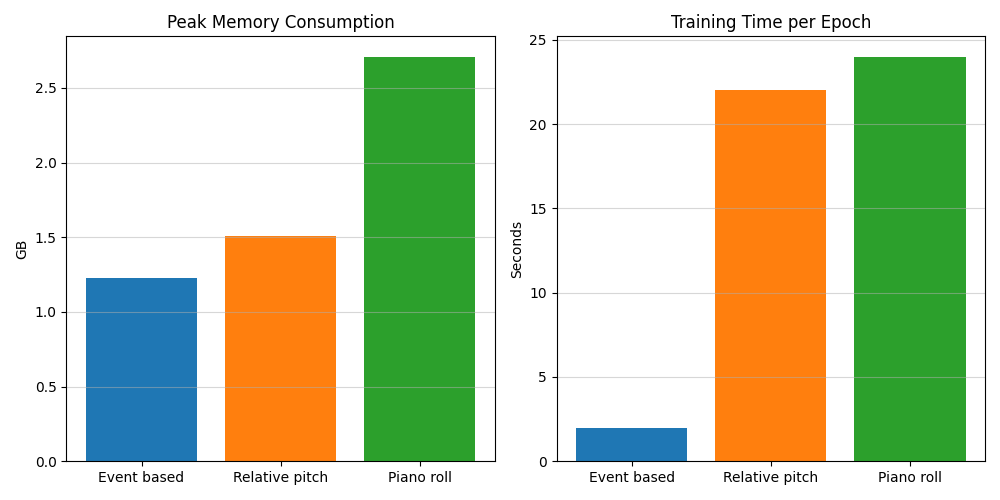
I have mentioned that the different representations have different memory consumptions and training speeds. For a machine learning problem, it can be important to make efficient models, in order to make it available for programmers without powerful machines.
In the following tests I trained the three different representations on a subset of the complete dataset I use, and gathered data on the memory usage and training time. Each model was trained locally using GPU on my M1 macbook pro.
Event based
This is the most efficient method. To represent the dataset takes 5298 inputs to the model, where each input is a vector of length 3, resulting in a total of 15.984 numbers fed to the model. This results in a peak memory consumption of 1,23 GB, making each epoch trained in 2 seconds.
Relative pitch
This second most efficient method is relative pitch, and it is much heavier than event based. To represent the dataset takes 31.496 inputs to the model, where each input is a vector of length 25, resulting in a total of 787.400 numbers fed to the model, resulting in a peak memory consumption of 1,51 GB. This method traines an epoch in 22 seconds. This is more than 10 times the time it took to train the model using event based representation.
Piano roll
Finally is piano roll. To represent the dataset takes, like in relative pitch 31.496 inputs to the model. But here each input is a vector of length 129, resulting in a total of 24.062.984 numbers fed to the model, resulting in a peak memory consumption of 2.71 GB. An epoch ends up taking 24s seconds to train.
What about the music?
While reading about memory consumption and training time for the different representations is interesting, we need to take a dive into the generated music. How does the music sound, and what are the characteristics of each model?
A disclaimer: In my research, I have put a limited effort into fine tuning the neural networks, since it is a comparative study. So while the melodies generated are of sub optimal quality, I think it still works as grounds for a comparison of the different models to see strengths and weaknesses to each representation. The network used is an LSTM, which is no longer state of the art for music generation, music generated using it has been described as sounding like a pianist playing without any intention or goal. This can be heard in the generated music.
Results
Event based
While it is super efficient at storing music data in a compact way, it generates very poor results, with little musical quality. One of the first things you notice is that every note has the same duration and with no silence between any notes. It also sounds somewhat random, like a four year old playing the piano with one finger. It also often plays sharp-notes, although it is trained on music in C major. You can listen to an example here. Only one is needed, because there is little variation in what it generates.
Piano roll
Being the most computational heavy seems to be paying off in terms of results. This method has managed to generate the most melodic melodies, it seems to be the most on beat, and often uses silence to make cool beats or dynamic sounding melodies. But it is still a varying model, and does often make vague music. It very often only wants to pick either silence or the same note as the previous note. Therefore I had to implement some randomness to choose whether it should pick its best note, or if it should choose a note that it deems the next or third best. Another problem is that it often sounds like it does not have any goal, while it often picks notes that are somewhat musically reasonable, it can struggle making music that feels intentional. I believe this is in part the result of using a LSTM.
Relative pitch
Being a compressed version of piano manifests itself in the output generated using this representation. You can find some of the benefits of piano roll like managing to use silence to make more dynamic melodies than event based representation did. The same drawbacks are also apparent, but to a larger degree. Relative pitch struggles with making non repetitive melodies because it almost always wants to generate a note that is either silence, the same note, two halftones up or two halftones down. This makes it repetitive and unmelodic. It also struggles with staying in one key.
Conclusion
From my own experience listening to what my models generated, it is clear that in these three representations, the quality of the output can be ranked in the same order as the memory consumption, and the clear king is piano roll. It is able to represent melodic structures in a way that the other two do not come close to. It is important to note that this is just my experiences exploring the different methods, and a different model, dataset or hyperparameters could show other results.