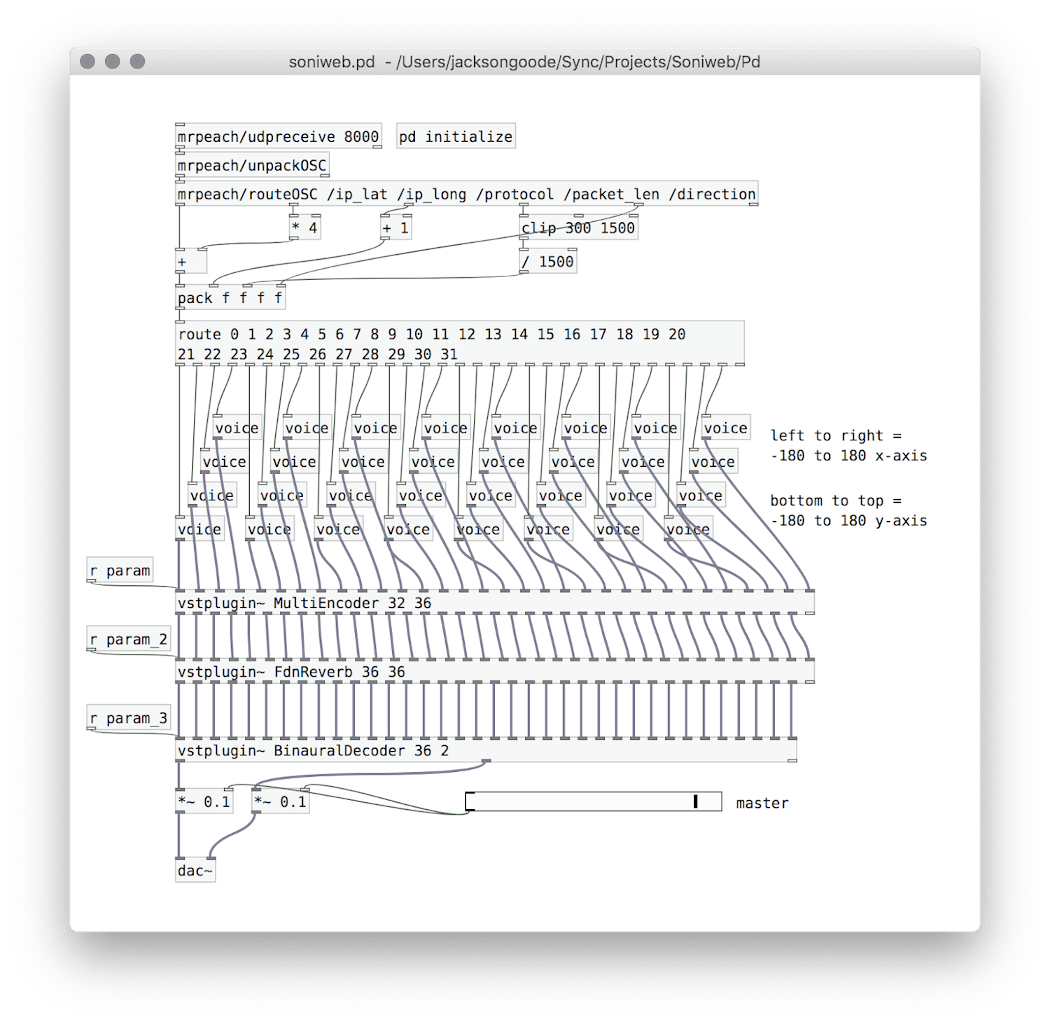
Soniweb: Epilogue
A Reworking of Soniweb
The Soniweb project was hurriedly completed within the span of about a week. However, in rushing through its implementation, there were a number of unique opportunities that would have been possible with the data we were receiving. Notably, the direction of the packets (whether they were being sent or received) was not considered in the process of our sonification. This information would be quite interesting to have conveyed through sound and provide interesting knowledge about when and how often is your computer uploading information to some other server.
One of the issues I have with sonification is the reasoning (or lack thereof) behind how aspects of data will be sonified. I feel this is a essential point of interpretation artistically that is missed by a lot of sonification projects in the pursuit of making them sonically “beautiful”. Too often the decisions that are being made are not necessarily drawing out acoustic features that parallel the relationships within the data. To this end, I wanted to make three adjustments to the Soniweb project. The first would replace sample playback to synthesized sound at the heart of the sonification, second would focus on shaping the synthesized sound in an extended range of parameters like envelope and pitch based on the features of the incoming packets, and third would be a general optimization of the python script and Pd patch to prevent stuttering or audio glitches during normal use.
From samples to FM synthesis
Our first version of Soniweb used pre-fab samples for each of the different protocols (UDP, DNS, TCP, etc.), meaning there was a considerable amount of processing in simply reading these samples into memory to play in parallel. In the previous version, there was noticeable pops and stutters as a result of web browser usage (page loads), Wireshark’s backend listening to packets, and Pd producing an ambisonic environment. So, one major reason in replacing samples with a short generated FM synth would be the benefit it might have on CPU usage and memory within Pure Data.
Sonification of direction
It’s not totally obvious how one goes about representing motions like approach or retreat. However, one nice point of reference is the Doppler effect, the reason firetrucks seem to have a higher pitch when driving towards the listener and a lower pitch once they have passed. This might be the best feature representative of acoustic motion along with increasing/decreasing volume.
With this information I planned to give the sense of a sound arriving and departing by creating envelopes that had a short attack/long decay (departing) and long attack/short decay (arriving), each coupled with the proper pitch transformations one would observe with the doppler effect (departing - pitch falling, arriving - pitch rising). However, due to the massive number of packets that are received at once, anything longer than half a second for a single sound would quickly become overwhelming. Thus, a lot of tinkering with the timing and duration of each of these transformations was needed in order to make their different both intelligible and musical.
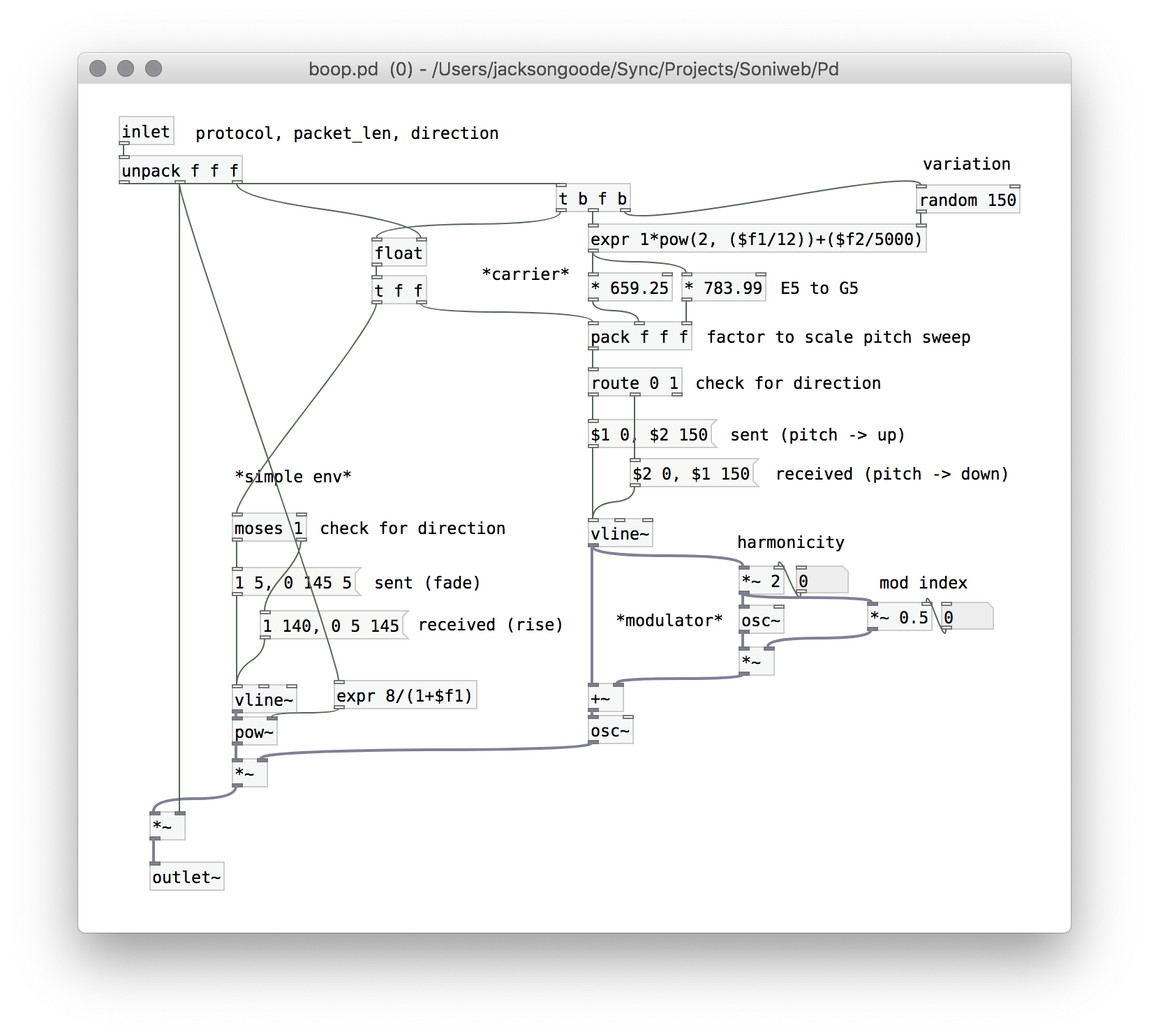
Filtering
Because there would be potentially dozen of packets coming within a single second, I decided to restrict this stream by 1) limiting the packet size and the frequency that packets could be registered in the python script and 2) shortening the max duration of the sound each packet will make to 150ms in Pd. These changes came after a number of other tests to see if limiting the packets by duplicate IP’s (no packet can be sent from the same IP in succession) and by duplicate packet size. Both of these alternatives seemed like strange modifications to the data stream and were workarounds for my desired outcome - fewer packets at once.
So, after checking the very scarce documentation of pyshark, I found there was a way to grab the time that a packet was received and restricted the interval between packets manually (5ms). I also made sure that sequential packets of the same size (such as when loading an image) have a subsequently quieter sound.
# Set up capture and filter by host IP and packet size
capture = pyshark.LiveCapture(
interface="en0",
only_summaries=True,
bpf_filter="ip and host "+host_ip+" and length > "+pkt_len)
for packet in capture:
# Restrict flow of packets
pkt_time = float(packet.time)
delta = pkt_time - prior_time
if delta > .05:
prior_time = pkt_time
# To OSC
try:
# For reappearing packets of same size - reduce gain
if prior_len == packet.length:
client.send_message("/packet_len", int(packet.length)/10)
else:
client.send_message("/packet_len", int(packet.length))
prior_len = packet.length
There was also a helpful flag within pyshark I had overlooked. The “only_summaries” flag when setting up the LiveCapture significantly reduces the information each packet carries when it enters python. Including it likely made the entire script more efficient as the information I needed from each packet still existed within just the summaries.
Results
Interestingly, the replacement of sound samples with synthesized sound did not initially reduce the CPU usage of the script on the computer I was testing with (a 2013 Macbook Pro). This may simply be a result of how intensive the setup for testing this program but also that I had made quite extensive changes to the structure of the program as well. Both the script, Pure Data, and a web browser (or web intensive application) are needed to run to “feed” Pure Data packets of data. With all of these applications running, Pure Data does struggle a bit and some pops and stutters when webpages are loading, though I have noticed that this behavior with audio interruptions is common to other applications like Zoom when there is intense web traffic happening at once.
After reworking the filtering system and tinkering a bit with the quality of the reverb I added, I think I ended up with something quite nice. Here’s a short video, please wear headphones to experience the full effect. The code and patches will be posted soon.