Sonification of Near Earth Objects

Introduction
How can we sonify data about objects in space passing by Earth over a chosen timespan, in a way that conveys characteristics of the objects?
As a part of a two-week workshop in the Sonification and Sound design course, we worked on the development of a self-chosen sonification project. For three days we explored how to design and build an auditory model of Near-Earth Objects (NEO) with data collected from NASA.
We intend to make future NEO events accessible for people by turning it into an auditory composition. As they orbit the Sun, NEOs can occasionally approach close to Earth. A “close” passage astronomically can be very far away in human terms: millions or even tens of millions of kilometers. These immense distances in space are hard to grasp for us living on earth. We hope that our auditory display will provide a unique (sonic) view on near-earth objects as they pass by earth. To do this, we need to overcome the challenges of getting data from an online source, parse the data in a way that creates a sound at the right time and design a sound that conveys the characteristics of each data point in a clear manner. Ideally, our auditory composition should be self-explanatory upon listening, but we are aware that without having any background describing the composition and its elements, listeners might experience difficulty knowing what they are listening to.
The user of the system will be able to select a timespan into the future, and then listen to a composition generated from the data. As the selected timespan could be a year or more, we decided to scale one year of events down to 6 minutes (30 seconds per month). As a user of the system, you will be listening to the events happening over time with physical parameters like velocity, magnitude and distance of the NEO shaping the sound of the object.
Theory, background and similar work
Sonification is described by Gregory Kramer and colleagues (2010) as “the use of non-speech audio to convey information”, and the sonification criteria specified by Thomas Hermann (2008) are met by our project:
- Sound has to reflect properties and/or relations in the input data.
- Magnitude → tone quality
- Nominal approach data + velocity → amplitude/doppler effect
- A precise definition of how interactions and data cause the sound to change must be provided.
- Our blog post provides this additional information.
- Sonification has to be reproducible so that the same data and interactions/triggers must result in structurally identical sound, which does not imply sample-based identity.
- Our model can be reproduced and is not sample-based.
- The system can intentionally be used with different data, as well as in repetition with the same data.
- Our model is meant to be used for any time frame extracted from the API
Our work was inspired by a sound installation made by Øyvind Brandtsegg called VLBI Music which also uses astronomical observations as a source for sonification. Please take a look at this blog, written by our fellow student Eirik Dahl, which describes Brandtsegg’s installation.
System
For our project, we chose to work with data provided by the SBDB Close-Approach Data API. This API contains a database with all the future NEOs, and we are able to sort and filter the data with query parameters when building the URL.

We decided to use Max/MSP together with Node for Max. Node for Max was used for data retrieval and extraction, and Max/MSP for data processing and sound generation. We have been able to retrieve the selected data from the API using HTTPS requests. The parameters we extracted from the data were time and date, velocity, magnitude and distance (Fig. 2). We then sent them as arrays to Max/MSP for further processing (Fig. 3).
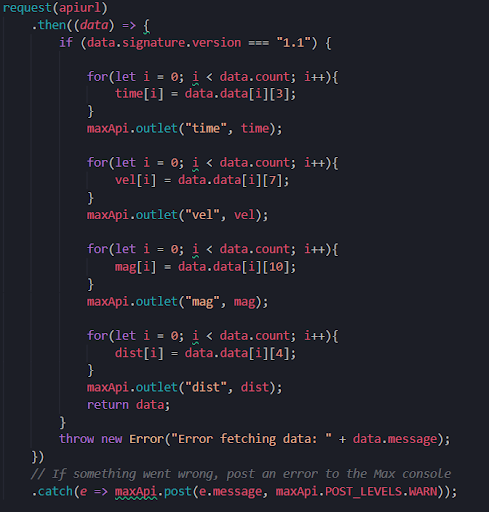
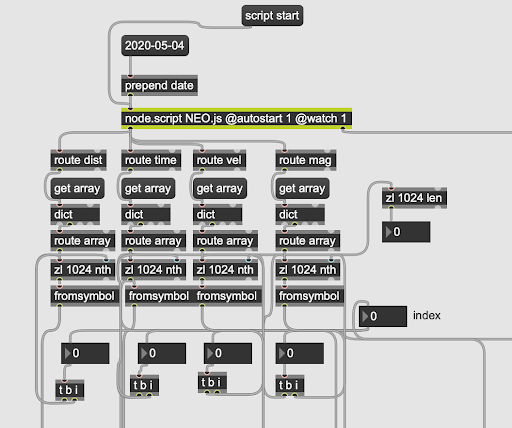
The sound from our system gets generated as each entry in the dataset gets passed to a synth voice in Max/MSP. Here, the distance and velocity gets used to create a model of the sound passing by, creating a doppler effect, much like the sound of a car going past at high speed. The magnitude of the object gets mapped to the pitch of an oscillator, creating a single tone for each object.
Timeline

Progress after the end of the course
The last day of the course, we presented an example of our system using randomly generated mock data played at slightly varying intervals. We still had not cracked how to read each entry of data at the correct time, so the sounds were only slightly varying and were not based on real world data. After the end of the course, we continued to develop a solution that would create a sort of timestamp based on the date of each object. With this we could calculate the delay between each entry to the next and pass the data to the sound generation in Max/MSP at those intervals.
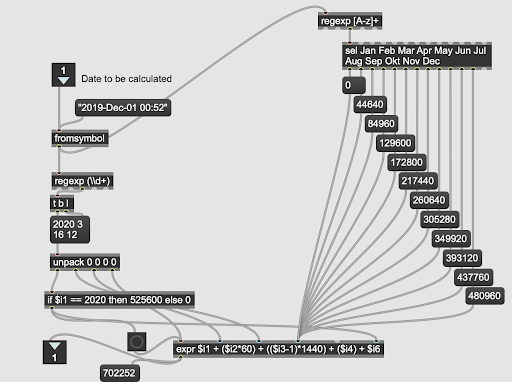
In the end, we managed to use a naive conversion of the date in Max/MSP (Fig. 5) to get the number of minutes after the start of each year and then scale it to get the delay in milliseconds. The solution isn’t generally applicable, meaning it only works for 2019 and 2020, but it is possible to improve the function to make it usable with any year and give the correct time, even with leap years.
This solution made it possible to use the correct data for sonification and is the key for the end result presented in this blogpost. In addition, the scaling of data to sound parameters was tuned to create more distinct sounds based on the object’s characteristics.
Here you can hear an example of how the NEO data is sonified by our system:
Reflection
The main challenges for the project were the use of the unfamiliar tool Node for Max and the data file (JSON) format which made it difficult to work within Max/MSP. It is important to mention that the decisions we made regarding the relations between the NGO parameters and the sound parameters, were based on a short discussion we conducted within our group. We decided to go with what seemed, at least to us, to be a clear and obvious connection of sound elements and NGO parameters. We view the presentation of a clear dataset, being able to implement the data with Node.js and developing the sound generator within Max/MSP, as our main achievements. In the end, we made the system work mostly as intended, resulting in sound from data.
Please take a look at our project files in the Code repository.