Audio Codecs and the AI Revolution
Introduction
Audio codecs are something we experience nearly every day, even if we don’t know it. From the audio you stream from Spotify (other streaming services are available) to the voices of your classmates or colleagues that you hear on Zoom, it is all compressed using an audio codec. So, what is a codec?
An audio codec is essentially an algorithm for changing the representation of an audio signal. It is often tied up with compression to reduce the amount of storage required. All codecs must include an encoder, which turns a raw audio signal into an encoded format, and a decoder, which does the opposite.
Traditional Codecs
One of the most popular audio codecs of the past two decades is MP3. You will probably recognise MP3 as an audio file type, but it also the name of a codec. The MP3 codec made waves (get it?) because it can compress audio to around 10% of its original size – roughly 1MB per minute of audio. In this case, the MP3 file is the encoded format, which is decoded during playback.
Another popular codec, albeit one with less brand recognition, is Opus. Opus is designed primarily for real-time applications. When you hold a voice call on WhatsApp or Discord, your microphone audio is encoded on your computer using Opus, sent over the internet to your friend, whose computer decodes it. Opus is specifically designed to encode at very low bitrates – that is, to compress audio so that it is represented by only a small number of bits per second, in turn using less of the available bandwidth on your home Wi-Fi or mobile network. It is also designed to be low-latency, meaning it introduces only a minimal amount of delay during the encoding and decoding processes.
Traditional codecs like MP3 or Opus leverage psychoacoustics and fancy maths to compress audio. They start by removing anything the human ear won’t hear – frequencies above the range of human hearing or sounds masked by other sounds, and then use mathematical tricks like Fast Fourier Transform to represent the signal using less information.
Audio Codecs & The AI Revolution
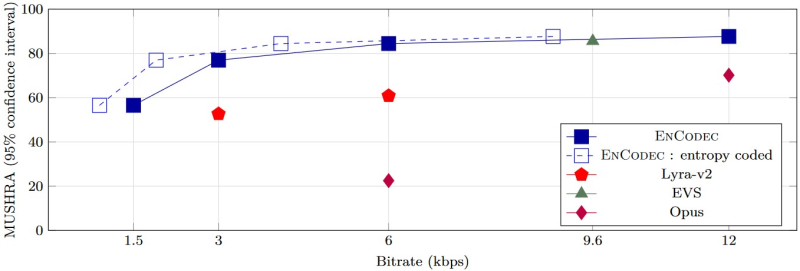
Machine learning is quickly making its mark in every arena of technology, and audio codecs are no different. The last three years have seen the release of several new audio codecs which use machine learning, rather than the traditional psychoacoustic and mathematical techniques, to compress audio. Prominent among them are SoundStream, Lyra, which is developed by Google, and EnCodec from Meta.
EnCodec is particularly relevant to network musical performance. It can encode wide-band stereo audio signals to bitrates as low as 3kbps while maintaining significantly higher quality than Opus at the same bitrate. SoundStream and Lyra are similarly impressive, although they are intended for compressing speech rather than music. Listen to the audio clips below to hear Opus and EnCodec in action on a sample of a string quartet:
ML Codecs for Network Musical Performance
What advantages do these new codecs offer for network music applications? Primarily, they may allow us to perform network music over a much wider range of networks. At MCT we are spoilt by the LOLA network, which is our gigabit local network used solely for music research. However, by encoding music to the small bitrates made possible by ML-enhanced codecs, we may be able to rehearse and even perform music over standard consumer Wi-Fi and even mobile networks like 5G.
Of course, there are some problems a snazzy new codec won’t solve. We’re still ultimately limited in terms of latency by the speed of light – sending audio over fibre optic cables from Oslo to Sydney takes a minimum of 60ms simply due to the laws of physics. However, ML-enhanced codecs may help to democratise network music performance, bringing it outside of the classroom and into the hands of the average home musician. That is something we can all get behind.
Watch the Video
References
- S. Hacker, MP3: the definitive guide, 1st ed. Sebastopol [Calif.]: O’Reilly, 2000.
- ‘Opus Codec’. https://opus-codec.org/ (accessed Apr. 22, 2023).
- Défossez, J. Copet, G. Synnaeve, and Y. Adi, ‘High Fidelity Neural Audio Compression’. arXiv, Oct. 24, 2022. Accessed: Apr. 08, 2023. [Online]. Available: http://arxiv.org/abs/2210.13438