CLAP Models and How To Make Them
As the meeting point between machine learning, language, and audio, Contrastive Language-Audio Pre-Trained models (CLAP) has potential for a plethora of language-aligned audio applications, including:
- Zero-Shot Classification
- Instruments, Voice Emotion, Music Genres, Counting Speakers and much more!
- Class Separation
- Music Retrieval
- Automatic Captioning
- Audio Content Filtering
- Sound Event Detection
Additionally, contrastive representations have been used for conditioning Text-To-Audio systems. So, if CLAPs are so great, how do they work?
Contrastive Representation Learning
The bad news is that such an architecture is quite complex to build from the ground up. The good news is that we can use pre-trained models within our contrastively pre-trained model, which can then be trained pre-integration in larger audio systems. Neat! All we need is a language model (BERT, RoBERTa, or T5 are common choices) and an audio model (HTSAT or PANN for instance). Projecting their logits into the same latent space using an appropriate loss function will give us the desired result.
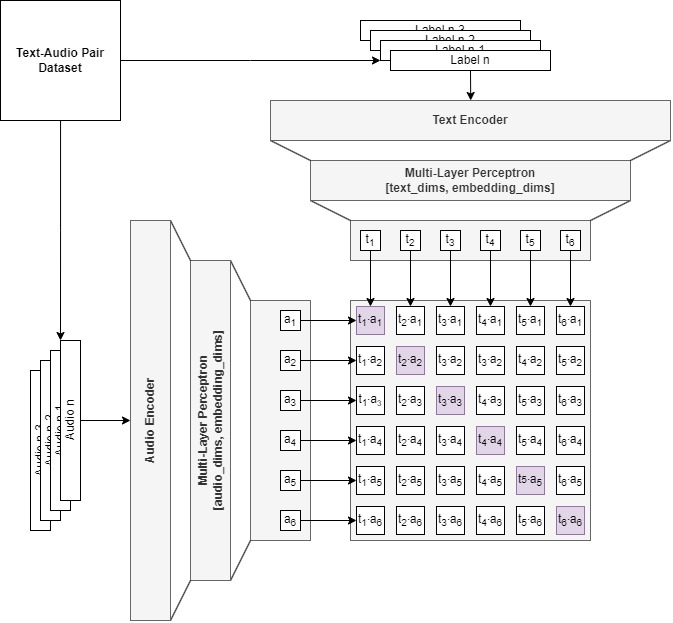
A contrastive loss function will be able to pull text logits and audio logits that belong together closer (positive pairs), but repell those that do not (negative pairs). What does such a loss function look like? I’m glad you asked! You can find code to get you started on my UCS-CLAP Github.
CLAP Comparison
I recently compared two CLAP models through the embeddings they produce, and through my experiments I can safely say that I am 76% confident that inspecting the proximity of CLAP embeddings through a 2D PCA plot gives a solid estimate of classification accuracy!
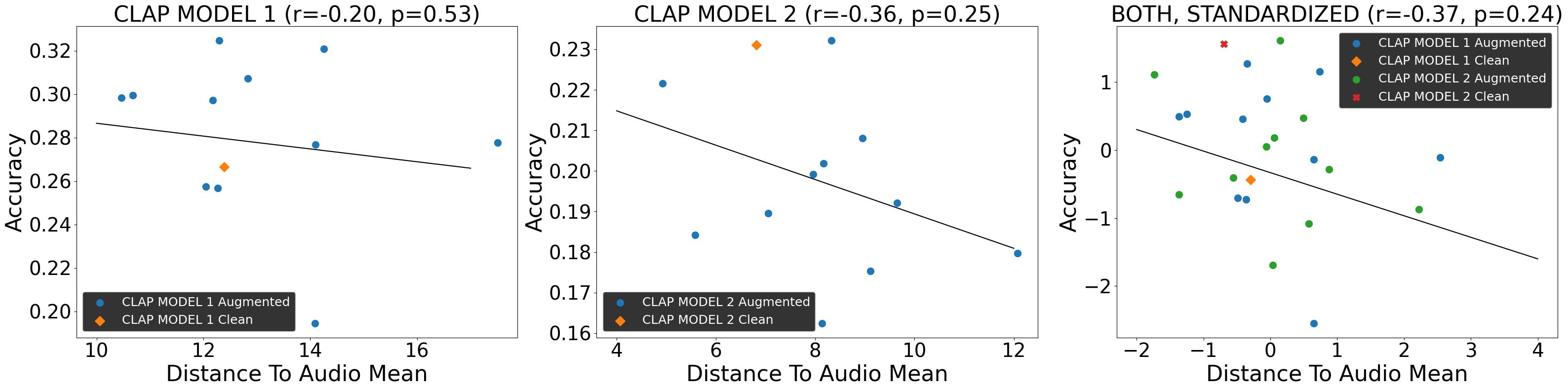
Disclaimer: these findings arenot backed by the statistical power necessaryto say for certain :(
Dataset & Code
Should you want to recreate my results, you may get audio embeddings here. Notebooks for the project and a reproduction guide may be found on Github.
Acknowledgements
My thesis was made possible with help from Stian Aagedal and Peder Jørgensen of HANCE.AI. I would like to thank them for their continued support and for granting me access to the entire Soundly audio collection for my work.