Piano Accompaniment Generation Using Deep Neural Networks
How can you generate piano accompaniments to a given melody using machine learning (ML)? That was my question. The answer, my friend, seemed not to be blowing in the wind, but revealed itself after extensive googling, trial, and error. My goal was to somehow generate piano accompaniments by conditioning the ML model on melodies. To do so, I had to look into the field of Natural Language Processing (NLP) and deep neural networks. I settled on working with symbolic music representation in the form of MIDI for my project, not raw audio. There has been a lot of research in translation applications using ML. Let’s pretend that melodies are Chinese, and accompaniments are Swedish. Now we simply need to translate the Chinese melody into a Swedish accompaniment. Easy, right? Not when you’re completely new to the field, as I was. But I slowly and steadily managed to learn some basics of ML translation, and a lot of general ML theory along the way.
Sequence to Sequence
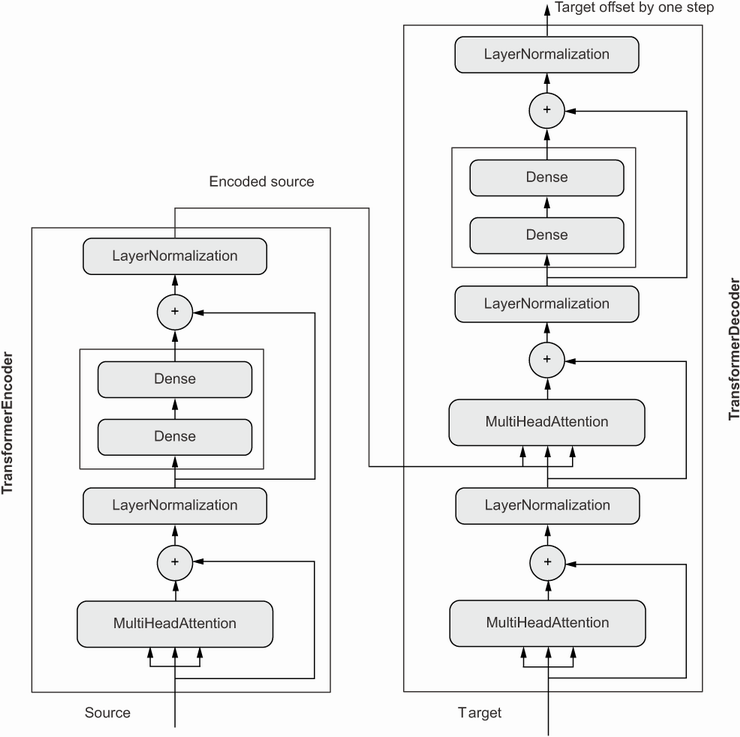
Translational tasks are usually tackled by using sequence to sequence (seq2seq) models. This architecture takes one sequence in and spits another sequence out. One of many challenges is that the sequences probably won’t be of the same length. And especially for my use case, where there should be several more notes (analogous to words) in the generated accompaniment than there will be in the incoming melody. One ML model design which has gained much attention (pun intended) the last years, is the Transformer model [1]. This model uses self-attention mechanism to learn the relationship between notes and can potentially learn long-term and high-level structures and phrases in music. This model performs even better than the Long Short-Term Memory (LSTM) layers, which previously was used by Google Translate, among others.
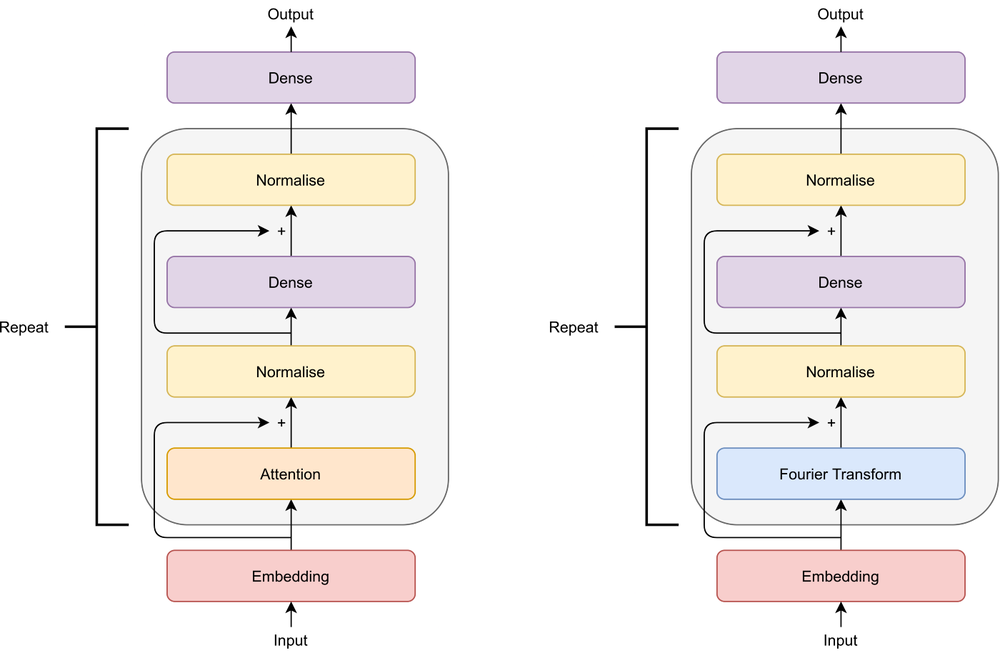
FNet
For my project, I chose to use the FNet architecture [3], which is a modification of the Transformer. Here, the attention layer of the encoder is exchanged with a Fourier transform layer to project the input sequence into the Frequency domain. This makes the model much faster, as multiplication in the frequency domain is equivalent to convolution in the time domain, while the performance is only slightly worse. I’m not too concerned about the accuracy scores anyway when working with a generative model like this.
Model Architecture
Seq2seq models are made up of an encoder block and a decoder block – in my case, the melody (source language) is fed into the encoder, and the accompaniment (translated language) is fed into the decoder when training the model. The encoder output is connected to a multihead attention layer in the decoder, to condition the accompaniment generation on the melody, while the decoders output is the predicted accompaniment. When the model is used for inference/generation, you’ll still feed the encoder with the melody, but the decoder will only receive its last predicted output token at any given step. (You can also feed the decoder a portion of the original accompaniment to give it a flying start, as I did when prediction my accompaniments.) Output token you say, what’s a token?
Tokens
The food for seq2seq models is tokens. Tokens would usually be a word representation in an NLP task. For symbolic music translation, this could be a note. There are several ways to tokenize music, and I chose to use a modified version of the design found in both Google Magenta’s Performance RNN and in the research done by the creators of my dataset [4]. I encoded MIDI notes into the following four categories:
- 128 note-on events (One for each of the 128 MIDI pitches – to start a note)
- 128 note-off events (One for each of the 128 MIDI pitches – to release a note)
- 32 time-shift events (Making 32nd notes the shortest possible time-shift)
- 32 velocity events (MIDI velocities quantized into 32 different values)
Dataset and processing
As my dataset, I chose the mentioned POP909 dataset, consisting of 909 Chinese pop songs. I wanted to work with popular or groove-based music, as much research has been done using classical piano music. This dataset conveniently had MIDI files with separated tracks for melody and accompaniment, which made the whole process easier for me. I chose to quantize the MIDI files into a 32nd second note resolution and chop the files into 32 bar segments to expand my dataset. Now, I only needed a model to train!
Model training
As my tool for building a machine learning model, I used the Keras ML framework, which is a part of the TensorFlow library. I spent a lot of time in building the model and tweaking different hyperparameters to make it perform in the best way possible. In the start, I used my poor old laptop, and kept it running overnight. (Disclaimer: Do not try this at home! I was a bit worried if the laptop would heat up too much during sleepy time.) After a while, I switched to using UiO’s ML Nodes. This, in the end, made it possible to fit my model in time. The final training of 695 epochs took about 6 hours and 45 minutes using 2 GPUs on the ML Nodes, while it would’ve approximately taken 10 days and 15 hours on my laptops CPU. (20 seconds per epoch vs 22 minutes pr epoch.) In the end, I chose to also train a vanilla Transformer model, to compare with the FNet.
Accompaniment generation
In the end, I was quite surprised how the generated accompaniments turned out. It played in the same key as the melody, but the timing and rhythm was oftentimes a bit off. The model seemed to be able to generate accompaniments with some musical phrases and elements audibly present. My virtual pianist is not replacing a professional accompanist anytime soon and will not always sound completely sober. But hey, it works better than I expected it would. Below, you can take a listen for yourself. Impressive or not, this has been a nice entry point for me into deep learning and music generation. I hope to expand my knowledge and experience in this field in future projects.
Audio Examples
The piano predictions below have the 256 first of 1024 tokens feed as an input condition. The first example was made by me recording “Make You Feel My Love”, to see how well my models performed on a completely different file with complex harmony.
“Make You Feel My Love” – Bob Dylan
Original Accompaniment
FNet Predicted Accompaniment
Transformer Predicted Accompaniment
“Song 186 – Segment 5” – POP909 dataset
Original Accompaniment
FNet Predicted Accompaniment
Transformer Predicted Accompaniment
References
[1] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural In- formation Processing Systems 30: Annual Conference on Neural Information Processing Systems (NeurIPS), 2017, pp. 5998–6008.
[2] F. Chollet, Deep learning with Python, Second edition. Shelter Island: Manning Publications, 2021.
[3] J. Lee-Thorp, J. Ainslie, I. Eckstein, and S. Onta-non, “FNet: Mixing Tokens with Fourier Trans-forms,” arXiv:2105.03824 [cs], Sep. 2021, Ac-cessed: May 04, 2022. [Online]. Available: http://arxiv.org/abs/2105.03824
[4] Z. Wang et al., “POP909: A Pop-song Dataset for Music Arrangement Generation,” in Proc. of the 21st Int. Society for Music Information Retrieval Conf., Montréal, Canada, 2020