Ensemble algorithms and music classification
For this machine learning project, I focused on applying supervised machine learning techniques to music genre classification. In particular, I wanted to look at how ensemble approaches can be used, how they compare to their base models and to each other, and whether they can tell me that the song I just wrote is shoegaze or dreampop.
Automatic music classification is a fairly well explored topic, and its techniques been put to use in music recommender systems in products such as Apple Music and Spotify. Using deep learning neural networks, high levels of accuracy have been achieved. There are some gaps however - listeners interested in music beyond the mainstream rarely receive relevant recommendations, and it is a widely know problem that recommender systems are prone to popularity bias.
So while much of the literature I came across focuses on very high level genres such as rock, pop and jazz, I chose 4 lesser known genres - post-punk, ambient electronic, dub and shoegaze. I thought it could be interesting to see how the techniques worked with less well defined genres/sub-genres, and I concede there might have been a touch of self interest driving this as well.
When it comes to the audio features used for genre classification, previous work in this field has found the most success using Mel Frequency Cepstral Coefficients (MFCCs). MFCCs are a great way of providing a compact view of the spectrum of an audio signal. The Mel scale emphasises the frequencies of the spectrum that correspond with what we hear as different pitches, so the machine learning model can get a better handle on whats going on in the music.
So I then fed all of these MFCCs into some ensemble algorithms and waited. Luckily, I didn’t have to wait too long, as these are traditional machine learning algorithms, and not those new fangled neural networks that take several days to tell you that you accidentally left the genre ID in the training data.
But what is an ensemble algorithm I hear you ask? Ensembles combine multiple weak machine learning algorithms into a single more effective model, and I used three different types: an ada-booster, a gradient booster and a random forest. The base model that these three ensembles use is the decision tree, so I also ran the data through one of those so we can see the effect the ensembles are having.
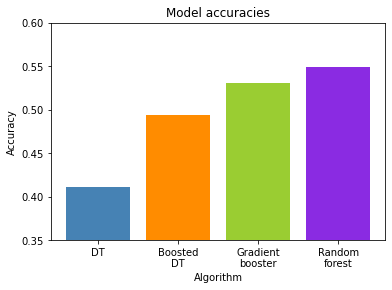
As you can see from the first figure, all ensemble methods provide a significant boost to the basic decision tree model, with the random forest yielding the best results here.
If we look at the performance of the individual genres, it was dub reggae that was most consistently identified correctly, and shoegaze that performed the worst. This is interesting, as other studies have shown reggae to be one of the harder genres to classify, but then these other studies have also managed to get 80-90% accuracy, and the best I managed here was 55%. Shoegaze is another interesting example - it can be seen that the ada-booster provided very little benefit over using the decision tree alone. Ada-boosters are know to be susceptible to noise however, and seeing as shoegaze tends to be pretty much noise with a lot of reverb added on top, this could explain the findings.
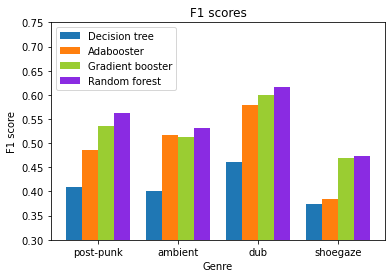
So my results weren’t massively impressive, but it was interesting and fun to learn about and play with the different ensemble algorithms.
What would I do different next time? I would experiment more with different features, rather than just sticking with MFCCs. MFCCs have obviously given some great results with convolution neural networks, but maybe the ensemble approach would benefit from a bit more exploration here.
Regarding AI driven music classification in general, I think its important to note that while state of the art approaches using deep learning have managed some impressive results, most music recommender systems still put more emphasis on more human centred approaches such as collaborative filtering, which analyses the listeners behaviour in comparison to other listeners, as well as simple human curation. Genre is a complex subject, and a concept that is not entirely embedded in the music.