Support Vector Machine Attempt
For MCT4047, I designed a Support Vector Machine(SVM) model which can learn to separate genres. The dataset used consist of a drastically different genre such as ambient and similar genres such as liquid drum and bass and hip hop. The reason for this choice of dataset was to hopefully combine a variety of feature extractions in efficiency with the most reasonable results at the end process. This project revolves around music recommendation. Streaming companies such as Spotify use user history and activities to recommend music that might be of similar taste of its users (Engineering, 2020).
Feature Extraction
For this project, I extracted nine features using Librosa. One of the most crucial extractions use was spectral flatness. As said on librosa’s page on spectral flatness, it measures how noise-like a sound comparing to its tonality (Librosa.Feature.Spectral_flatness — Librosa 0.8.0 Documentation, n.d.). Heavier genres could be describe as noise-like because of heavily distorted guitars and heavy harmonic processing. spectral flatness would be very appropriate to use as a value to separate genres. The other extraction includes RMS levels, spectral bandwidth, spectral contrast, spectral centroid, spectral rolloff and tempogram. The feature extraction took a very long time to execute due to the huge collection of music and file size. The extraction was designated with a label as well from the file name. However due to the nature of the very long processing, I then saved the information into a csv file using a pandas data frame which I then converted it back into a numpy array. Using a scatter plot through matplotlib, I first tried to experiment if I could find any meaningful correlations to ensure that I have the necessary feature extractions for this project. In the python file, there would be three scatter plots, plotting out correlations of RMS to spectral flatness variance, spectral contrast with spectral rolloff and RMS with spectral rolloff.
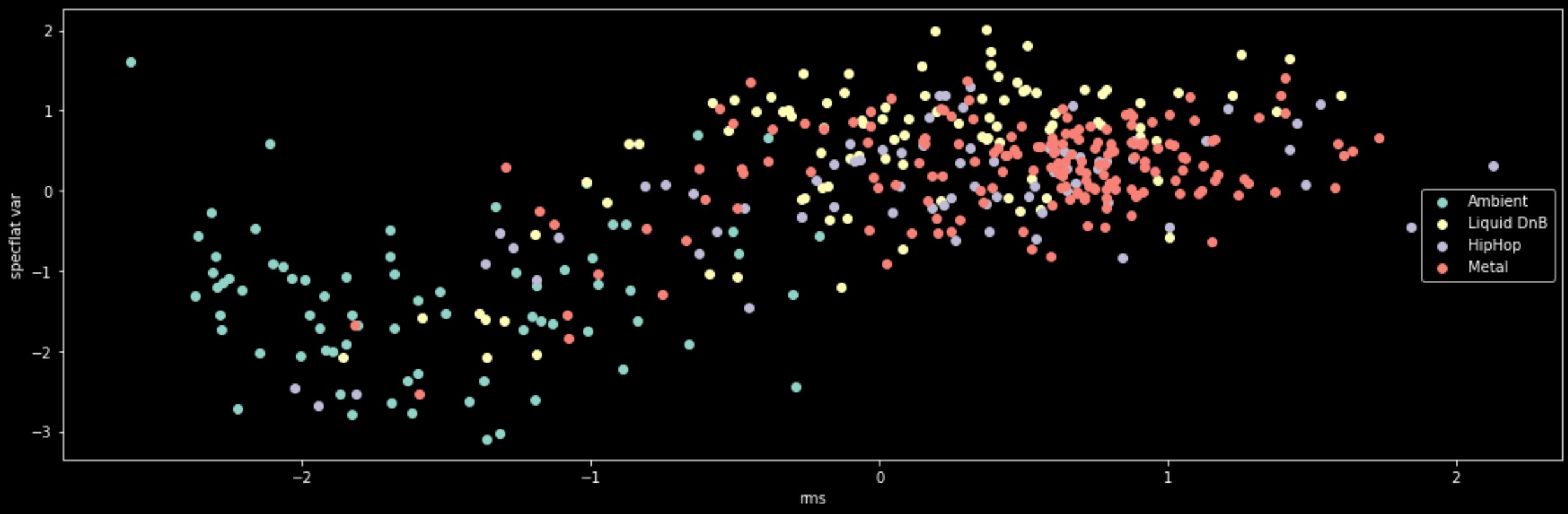 figure 1. RMS vs Spectral Flatness Variance
figure 1. RMS vs Spectral Flatness Variance
ML Algorithm
For this project, I will be using Support Vector Machine(SVM). The choice of SVM was rooted in the advantages in the way SVM handles multi-dimensionality as there will be nine features. The other reason for choice in SVM was to try to be memory efficient. The ethos behind the choice was to learn SVM well enough and try to squeeze out as much accuracy I can with handling high dimensionality without dimensional reduction.
Results
The accuracy mean is slightly above 0.8 . The value might not be useable in a real world solution which means there is still allowance for improvements.
Conclusion
The choice of SVMs was ideal in my situation. It had all of the advantages required for my project.
- Smaller Dataset
- Multi-Dimensional
- Memory Efficient