IR Reverberation Classifier using Machine Learning
Now MCT (music, communication and technology) course is in its second year - and finally we are covering Machine Learning! This is how my original expectations were, high hopes, large complex projects involving real time production of sound through learning computers, maybe even breaking to a new paradym of music technology, however…..
Machine learning is HARD!
From the first day, dreams were dashed and expectations slashed. Real time is possible, as well as sound generation - but its best to start with getting to grips with the basics. So, after this initial shock, I decided to settle down on a go-to of machine learning (ML), a classification problem (you know, like is it a dog or cat picture?). When thinking of what data to use, it was advised to use short samples when working with lossless audio. In this vein I though about reverberation impulse response files - short audio clips that represent the reverb in a space, such as a room or hall. These files can be convolved with audio to create a representation a how a sound will be projected in that space.
So, I aimed on teaching a computer how to differentiate between audio files that have had different convolution reverb applied. For instance, can a ML model know a sound of a dog barking in Taj Mahal compared with dog barking in a a toilet? For this experiment I used completely random short sounds for testing, such as a car engine or a violin or a brick hitting the floor for example. This was done to make sure it was not too easy for the model.
After much trail and tribulation a model was set up. Using three kinds of reverb as classes to be classified, and 150 audio samples as test data, it was time to extract features from the audio. In other words turn some aspect of the audio into statistical data so the computer can understand. This can be too do with the tonality or frequency spectrum - essentially you need to measure something to be able to compute it (a computer doesn’t really know what sound, or music, is!). This is one of the most important factors in preparing audio for analysis in ML algorithms.
I used Mel frequency cepstral coefficients (MFCC) as the main feature. This is a way to represent the frequency spectrum of a sound, in the Mel scale. It is very common with speech recognition. After some experimenting, this was the most effective in achieving the best results possible for the model.
Then this data gathered via MFCC is put through various different machine learning algorithms - K Nearest Neighbour, Support Vector Network were the most useful. Here are the results:
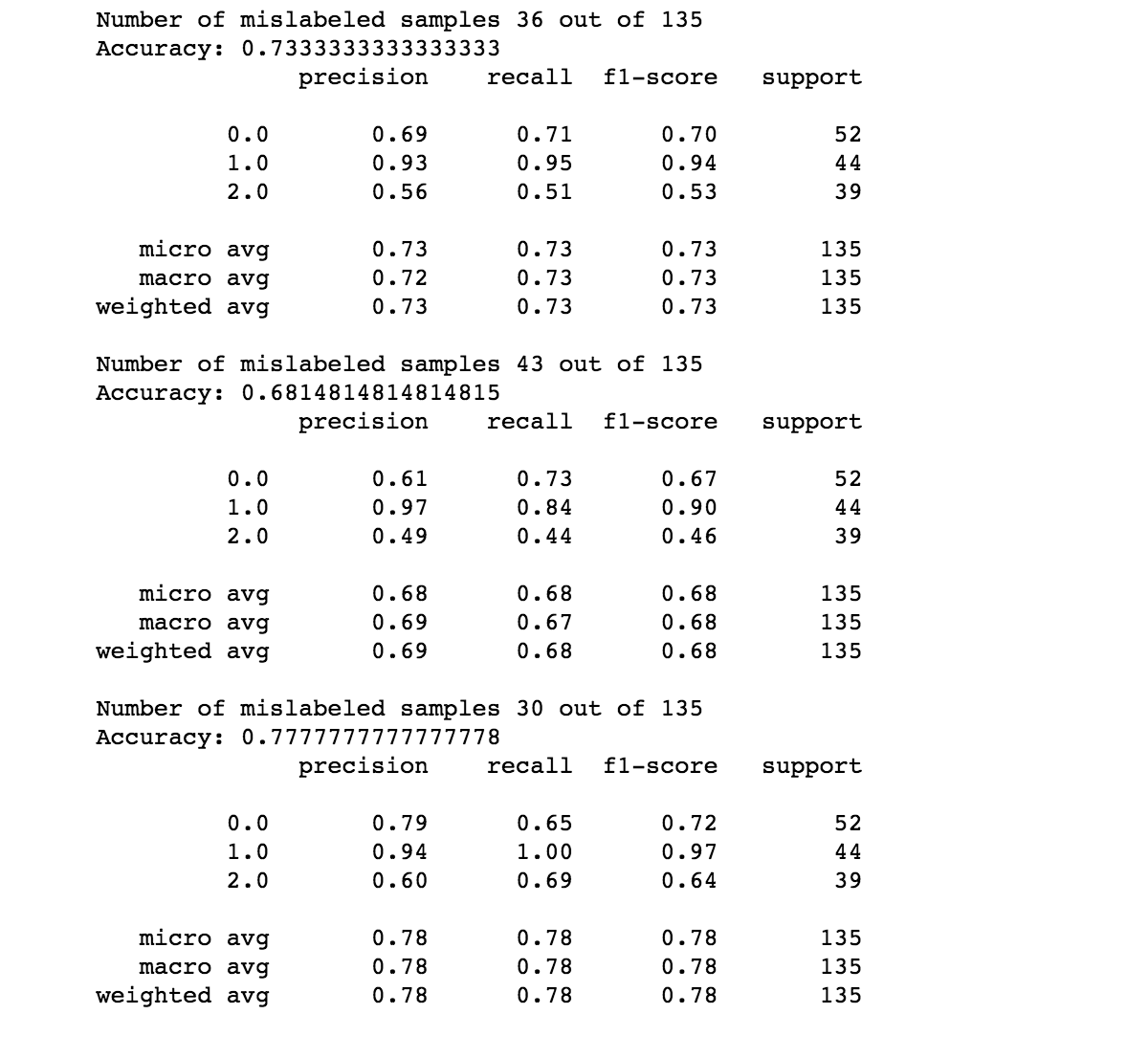
Results
Overall the project had some positive results, which I am quite pleased with; for two weeks time limit it was touch and go that it would work at all. Support Vector Network achieved the highest, most accurate score. Now to hassle google and get some masses of data for deep learning!