Triggering effects, based on playing style
Technology in collaboration with art could create creative solutions and achievements. In here we use machine learning in order to ease the work of player while playing an instrument.
Introduction and background
As a guitar player, while playing live, I can feel that it could be very useful to have a system in which engages and disengages the necessary effects, based on my playing style. This lead me to creation of a system, based on machine learning, which engages and disengages reverberation based on my playing style. For that the machine needs to learn how to differ between playing styles.
Feature Extraction
For the so called matter stated above, some samples were needed. Therefore I reorded two sets of 52 samples, with each 5 seconds lenght. A group of them represented the rhythm guitar playing style and the other represented the solo playing style. Also, I have to mention that since aesthetically having the reverb on Arpeggios was more efficient as well, I mixed some arpeggios with the solos. Here you can hear a sample, from each group of the files:
- Rhtyhm sample:
- Solo/Arpeggio sample:
After that, we have to consider the fact that, the machine needs to analyze and understand the audio files. For that there were few features extracted from the files and presented to the machine, so the machine could identify the audio files for itself. The language that was used for programming the system was python and the package that was used in the script to work with audio files was LibROSA. The main features extracted from the samples included RMS, Spectral Flatness and Chromagram stft (indicating the power of the playing). These features were extracted and were fed into the system. The files were clustered by an algorithm called PCA (principle component analysis). The reason for that, was to reduce the set of variables (features) to a small set that still contains most of the information in the original one. Below you can observe the graph that projects the two group of samples, based on their features.
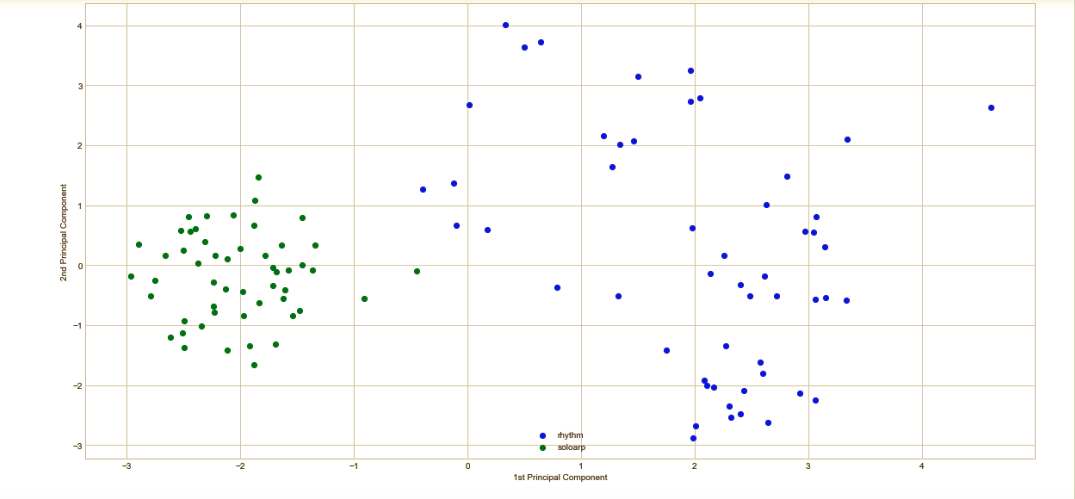
Classification, training and prediction:
For the classification and learning processs, a system called Support Vector Machine was used. This is a supervised learning system which is very efficient system for classification of such data. It finds a hyperplane in an N-dimensional space (N = the number of features) that distinctly classifies the data points. As it is shown below, it could classify the samples with a high accuracy.

Future work
The next step is implementing the system on a real situation. Although after implementation there is going to be a bit of latency in live situations, but in the case that more features could be added to the system, in regards to the automation of the effects, it definitely will worth going through it.