Classification of string instruments
During a 2-week intensive workshop in the course Music and Machine Learning I had to develop a machine learning system for the field of music technology. With no previous practical experience with machine learning (ML), this turned out to be quite a challenge. During the two weeks we got a broad overview over ML theory and practical ML in Python. Several example systems were shown during the weeks by our professor Stefano Fasciani, which would come in very handy when working on my own project.
A machine learning system uses ML algorithms to build a model based on data that is fed into it, which we call “training data”. This model can then make predictions on new data without being explicitly programmed. When choosing a project, it is important to know that the problem you want to solve cannot easily be explicitly programmed. Machine learning would then be overkill. Let’s say you want to automatically separate between the sound of a bass drum and a hihat. These can very easily be separated with a simple threshold on the frequency spectrum, and using machine learning to figure this out, would clearly be overkill.
My classification project
With my project I wanted to see if a machine learning system could separate between three instruments that have a lot of spectral similarities, and which seem quite similar to the human ear. These instruments are guitar, mandolin and banjo. All are string instruments, and for an untrained ear it can sometimes be hard to separate between them. It’s at least not as easy to separate as a bass drum and a hihat.
This process of separating between input data with machine learning is called classification. In classification a machine learning algorithm predicts a class/label based on a given dataset. In the case of classification, the dataset is labelled, which makes it fall under the category of supervised learning.
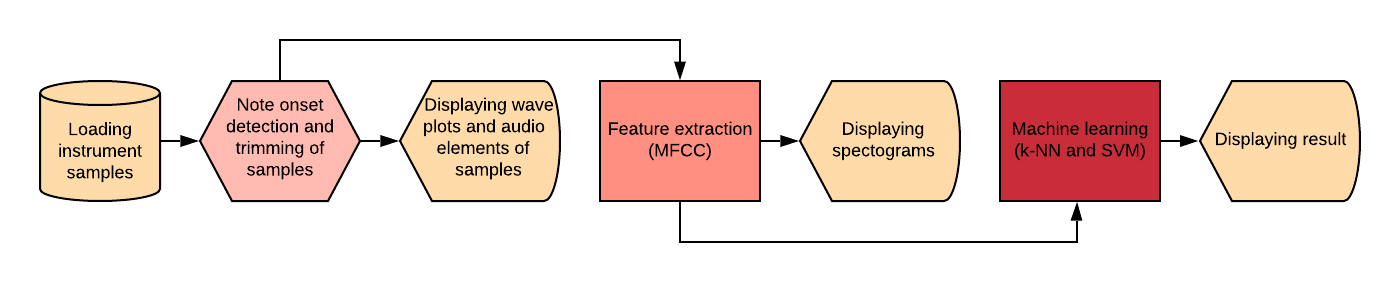
I can divide my system into three main processes:
- Data preparation (light red)
- Feature extraction (red)
- Model training and prediction (dark red)
The data
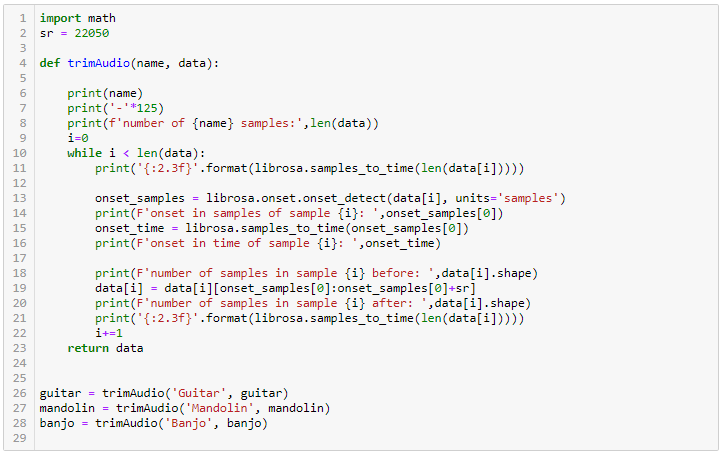
The data preparation part is where you would get rid of noise, silence etc. in the dataset; get rid of random variables that will mess up the classification. In my case I had 39 samples of each instrument. I chose to trim each file (total of 117) to last for 1 second from the first note onset. This was of course done with python code (with the help of a package called Librosa), or else I would have had a really boring time.
Feature extraction (MFCC)
The machine learning algorithm works with numbers. Which numbers is up to me, and of course it should be numbers that tells some characteristic of the data. I chose to give my ML algorithm something called Mel frequency cepstral coefficients (MFCCs). Pretty self-explainable, right? No, absolutely not…“MFCCs are short time power spectral representation of a signal and represents psychoacoustic property of the human auditory system”. Now, when that is completely clear for everyone, why do I give the ML algorithm this? Well, it turns out to be one of the most, if not THE most popular feature when working with speech recognition, genre classification, music insformation retrival and more. One of the reasons for this is that it tells something about the timbre of the sound. Exactly what I want to separate my instruments by, so great.
Model training and prediction
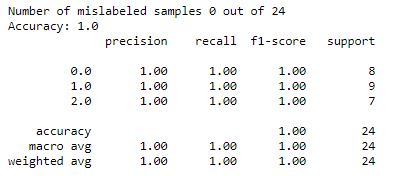
So, when I had the “timbre” of each sample of each instrument, I just gave 80% of the data to an ML classifier called support-vector machines (SVM) as training data, and 20% as test data, tweeked some parameters to make it throw my data into a higher dimensional feature space, and then a few ms later it told me that it had classified everything with a 100% accuracy. Could not be any better than that right? Turns out it is not a problem for a machine to classify between three similar string instruments, if you give it some good data that is.