Wizard_of_Vox
Wizard Of Vox is a gesture-based speech synthesis system. I have been fascinated by the flexibility of the human voice for a long time. The first two formants can be used as parameters that have a large amount of expressiveness, and can be applied to any broadband frequency sound source. Instruments can be “made to speak”. The combination of several sound sources in the human speech production system and several branches of resonant chambers in the oral and nasal cavities are also a fun challenge to model. Artificial voices are always a bit creepy, and this can be used artistically.
Theory
The prototype I devised in this project is based on the source-filter theory of speech, which posits that speech outputs can be analysed as the response of a set of vocal tract filters to one or more sources of sound energy. A source in the vocal tract is any modulation of the airflow that creates audible energy. For speech, there are two main categories of sources:
- Glottal constrictions
- Supralangyreal constrictions Glottal sounds can be voiced or unvoiced. Both the voiced and unvoiced sources (unvoiced as in whispering voice) are highly modifiable by the shape of the oral and nasal cavities. All sonorants (vowels, glides, liquids and nasal consonants) are characterised by what is termed as formants. In particular, the first and second formants have a large role in how we perceive sonorants. For this system, I have relied on these two formants (hereafter called F1 and F2) to control the speech synthesis. F1 and F2 were mapped to the accelerometer axes X and Y. By tilting the accelerometer right/left and backward/forward, I could thus easily access all sonorant within a short time period (fraction of a second).
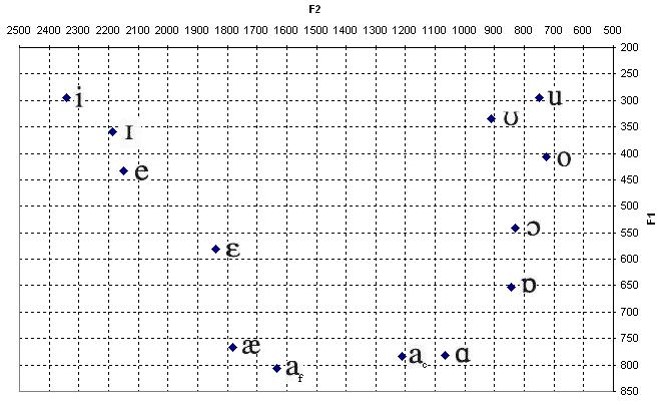
In addition to the glottal sources, supralangyreal sources are turbulence noise happening higher up in the palette, tongue, teeth and lips. These are independent of the glottal sounds, and they do not have formants as such. These sounds (most of what we call consonants) are characterized by the type of friction occurring. From now on I will call these source sounds obstruants, which is the linguistic term.
Synthesis
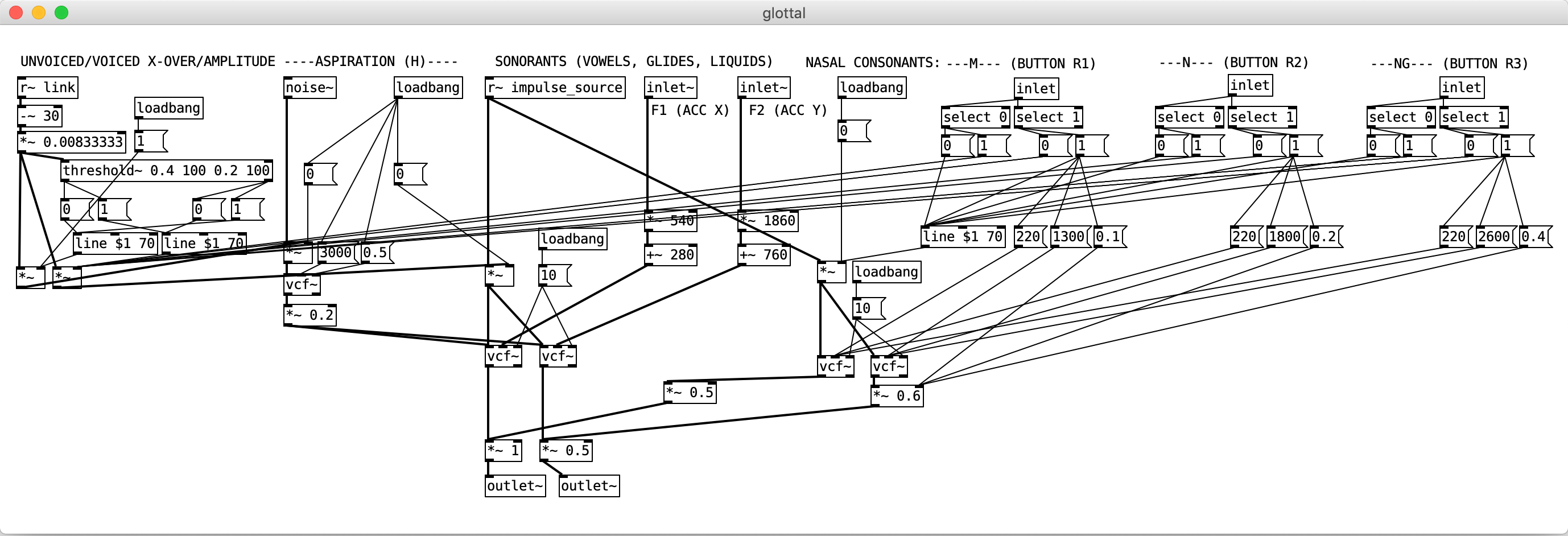
All these sounds have been modelled in pd using subtractive synthesis:
- Source sound for voiced glottal sounds: sawtooth wave (pd object phasor~)
- Source sound for unvoiced glottal sounds: white noise (pd object noise~)
- Source sound for unvoiced obstruants: white noise
- Source sound for voiced obstruants: sawtooth + white noise
- Filtering technique for sonorants and aspiration: formant synthesis (using the vcf~ object in pd)
- Filtering techniches for obstruants: band pass/band stop filtering
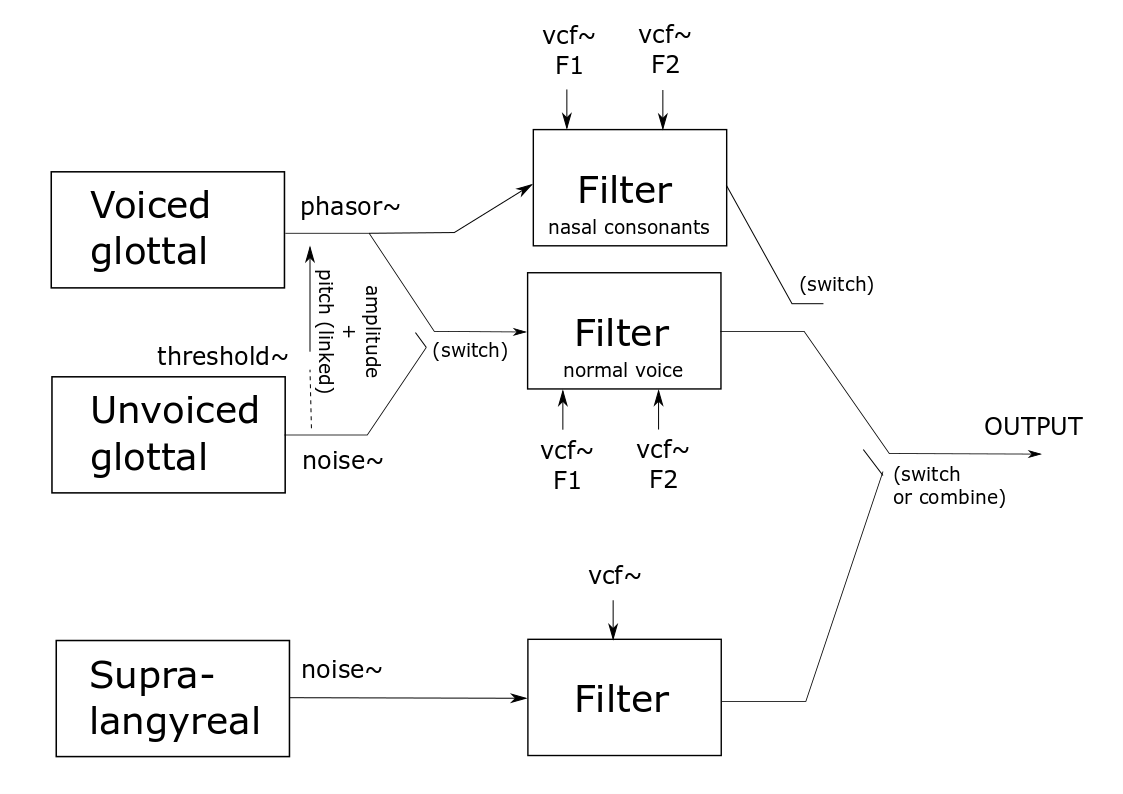
Mapping
Accelerometer X/Y controls the formants (F and F2) The flex sensor controls pitch and amplitude at the same time (the higher the energy, the higher the pitch). But the range of the flex sensor is divided into two separate regions. For the first 40 % of the range, the source is white noise, and this is meant to model aspiration (i.e. unvoiced) before voicing actually kicks in for the final 60% of the range. This makes it possible to simulate the breathiness of the human voice as it starts vocalizing. It also makes it possible to simulate the “H” consonant properly, because the phoneme “H” is actually different depending on the subsequent vowel. The “H” in “hello” is phonetically different from the “H” in “happy”.

Finally, there are seven different buttons triggering consonants. These are divided into three buttons for the nasal consonants “M”, “N” and “NG”, which have a voiced glottal sound source and thus modified by formants, and four buttons for the consonants “S”, “P”, “T” and “K”. For this prototype, I did not make triggers for more than these consonants, but the longer-term plan is to be able to trigger more consonants through the combination of these same buttons.
Considerations
Expressiveness: there is a much potential for expressiveness Playability: it takes practice to form intelligible speech with this system, but it is possible Virtuosity: it is possible to show a high degree of virtuosity using this system, with enough practice Aeshtetic aspects: it is a fun instrument to listen to, but it can cater to darker emotions (the uncanny valley effect) Audience perspective: this could be an engaging instrument to witness for an audience (the performer as a wizard creating speech by movement)
Reflections on feedback
working 100% at the time, as only three of the seven buttons were working and the flex sensor had the wrong resistor in the circuit. However, the review was overall positive. He mentioned that the system is a bit difficult to play with. I agree, and personally, I don’t consider this a weakness. Most interesting instruments are difficult to master. It is important to keep in mind, however, that this prototype uses sensors that were available in the Bela kit. For future iterations, I would like to control the accelerometer using a lever where the buttons are placed on the handle. And instead of a flex sensor, I would like to use a proximity sensor with high resolution.
References
Diehl, R. L. (2008). Acoustic and auditory phonetics: the adaptive design of speech sound systems. Philosophical transactions of the Royal Society of London. Series B, Biological Sciences.
Gawron, J. M. (accessed 2019). Chapter 1 Phonology. From a course compendium: https://gawron.sdsu.edu/intro/course_core/lectures/phonology.htm (Links to an external site.)
Mori, M., MacDorman, K. F., & Kageki, N. (2012). The Uncanny Valley [From the Field]. IEEE Robot. Automat. Mag., 19, 98-100.
Sawyer, J. (accessed 2019). The Acoustic Property of Vowels and Consonants. CSD 349: Speech and Hearing Science. Compendium text, Illinois State University. http://my.ilstu.edu/~jsawyer/consonantsvowels/consonantsvowels_print.html (Links to an external site.)
Smith, J. (2008). Speech Synthesizer. Documentation of university coursework. McGill University, Montreal, Quebec, Canada. http://www.music.mcgill.ca/~jordan/coursework/mumt307/speech_synth.html